Generalizable long-horizon robotic assembly requires reasoning at multiple levels of abstraction. End-to-end imitation
learning (IL) has been proven a promising approach, but it requires a large amount of demonstration data for training
and often fails to meet the high-precision requirement of assembly tasks. Reinforcement Learning (RL) approaches have
succeeded in high-precision assembly tasks, but suffer from sample inefficiency and hence, are less competent at
long-horizon tasks. To address these challenges, we propose a hierarchical modular approach, named ARCH (Adaptive
Robotic Compositional Hierarchy), which enables long-horizon high-precision assembly in contact-rich settings. ARCH
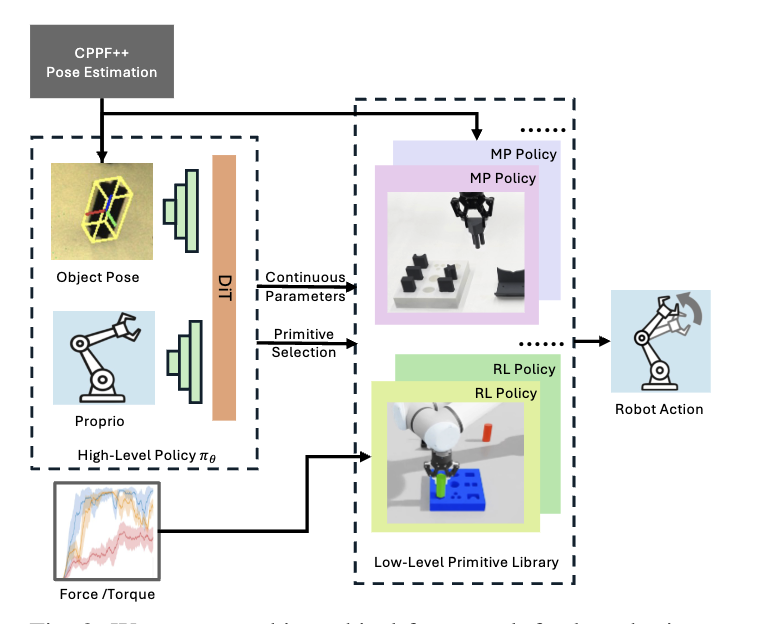
employs a hierarchical planning framework, including a low-level primitive library of parameterized skills and a
high-level policy. The low-level primitive library includes essential skills for assembly tasks, such as grasping and
inserting. These primitives consist of both RL and model-based policies. The high-level policy, learned via IL from a
handful of demonstrations, selects the appropriate primitive skills and instantiates them with input parameters. We
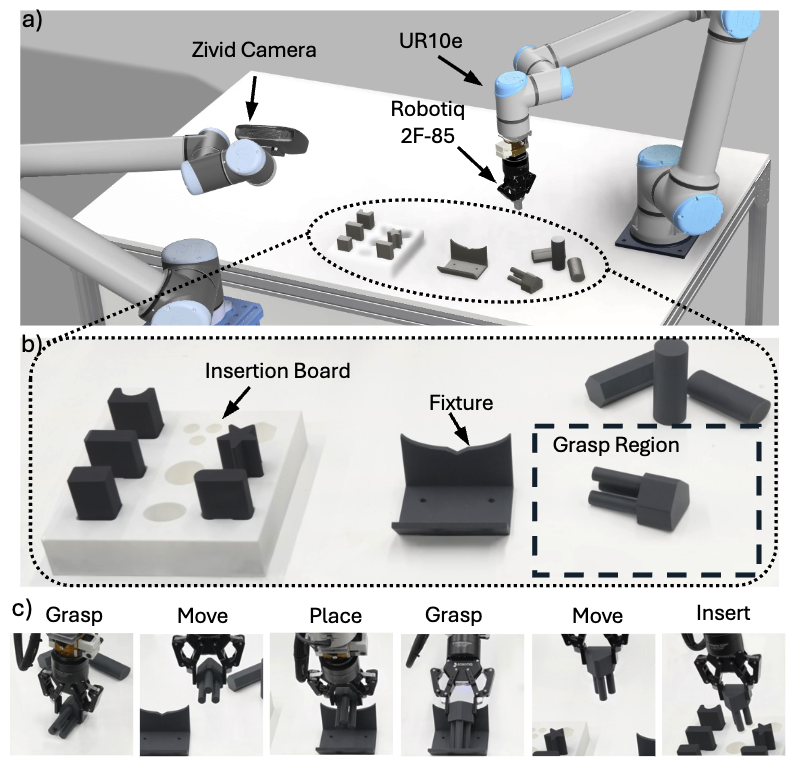
extensively evaluate our approach in simulation and on a real robotic manipulation platform. We show that ARCH
generalizes well to unseen objects and outperforms baseline methods in terms of success rate and data efficiency.